Технологии искусственного интеллекта выходят на новый уровень. Чаты – уже прошлое. Теперь задача “вывести” ИИ в реальный мир. Ведь полностью логично, что робот должен “понимать” наш мир, а не читать о нем текстом. Пока это малозаметный тренд, но он кардинально изменит технологии нашей цивилизации.
КАК ОБЪЯСНИТЬ ВАЖНОСТЬ ЭТОГО ВСЕГО ОДНОЙ КАРТИНКОЙ?
Посмотрите на этот скрин. Это видео, где крышка падает в воду и где зеркальный шар катится и показывает отражение. Это и есть самое неочевидное – нейронная сеть ДОСТРАИВАЕТ и ПРЕДУГАДЫВАЕТ физические изменения в среде. Волны от падения внутри прозрачной чашки моделируются как реальные. Отражение на зеркальном шаре – фотореалистичны. Это и есть СИМУЛЯЦИЯ законов реального мира внутри ИИ. Это следующий этап в развитии искусственного интеллекта.


Информация о спикере
Jim Fan (范麟熙) — исследователь и руководитель направления воплощённого ИИ (embodied AI) в NVIDIA.
Ключевые факты:
- Должность: Руководит группой Generalist Embodied Agent Research (GEAR) в NVIDIA — занимается созданием универсальных ИИ-агентов, которые могут действовать в физическом мире.
- Образование: PhD из Стэнфорда (лаборатория Fei-Fei Li), специализация — компьютерное зрение и робототехника.
- Опыт в OpenAI: Работал в OpenAI на раннем этапе, был свидетелем/участником запуска первого DGX-1 (система NVIDIA для ИИ-обучения).
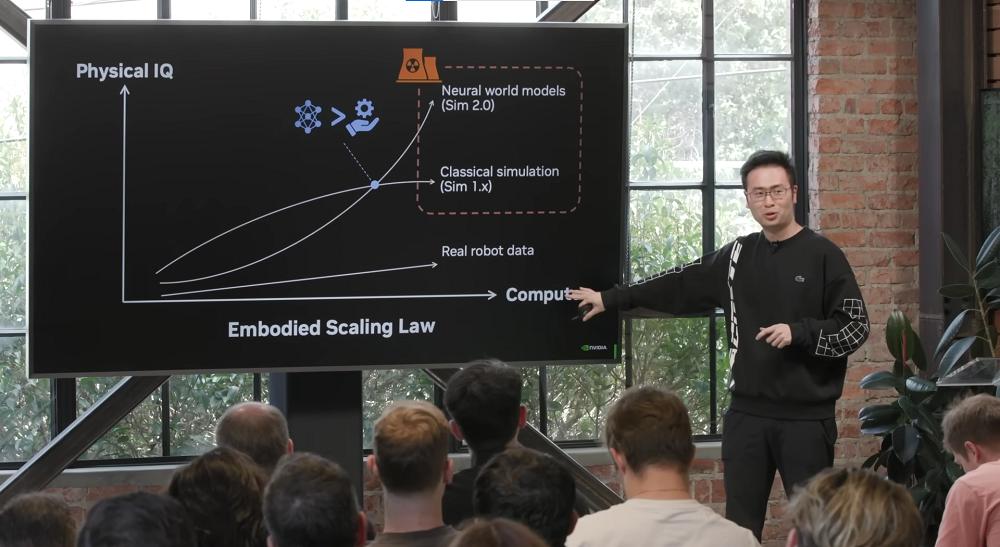
Робототехника входит в финальную фазу («endgame»), и сценарий развития уже известен. Он повторит путь больших языковых моделей (чаты с ИИ), но с заменой ключевых компонентов: мировые модели вместо языковых, эгоцентрическое видео вместо телеуправления, а World Action Models (WAM) заменят концепцию VLA.
Ключевые тезисы
- «Давайте помолчим минуту в память о нашем дорогом друге VLA. Они хорошо послужили нам. Покойтесь с миром. Да здравствуют World Action Models.»
- «Если видео-предсказание работает — действие работает.»
- «Вычисления = среда = данные» — новая эквивалентность в физическом ИИ.
- Видео как универсальный мост: пиксели объединяют разные роботизированные платформы (cross-embodiment).
- Scaling law в робототехнике: впервые показана предсказуемая зависимость масштаба человеческих данных и качества робота.
Важно понимать, что технические возможности уже достаточны для того, что мы видим в фантастических фильмах. Следущий апгрейд должен быть в програмном обеспечении.
Робототехника следует тому же скрипту, что и LLM, но с заменой фундаментальных концепций:
- Language Models → World Models (модели мира предсказывают физическую динамику, а не текст)
- Text data → Egocentric video (первичный сигнал — видео от первого лица, а не размеченный текст)
- VLA → World Action Models (парадигма Vision-Language-Action уступает место совместному моделированию мира и действий)
| Этап развития LLM | Что происходит в робототехнике |
|---|---|
| Pre-training | Предобучение на массивных данных физической динамики |
| Reasoning | Рассуждение и планирование в физическом пространстве |
| Automated exploration | Автоматический сбор данных и самообучение агентов |
Выступление от NVIDIA о дорожной карте развития индустрии. Что нас ждет?
Видео доступно с автоматическим переводом. Если у вас не открывается, то ниже подробная расшифровка выступления. Или по прямой ссылке
Расшифровка выступления
01:42 — The Great Parallel («Великая параллель»). Путь будет аналогичен LLM-треку.
Пока технология в самом начале экспоненты развития.
03:31 — Финальная фаза робототехники / Почему VLA недостаточно
Проблема VLA (Vision-Language-Action):
Хороши для семантической генерализации, но плохо справляются с незнакомыми физическими движениями в новых средах.
Требуют огромного количества повторяющихся демонстраций для каждой задачи.
Переход: Нужна новая парадигма, которая изучает физику мира напрямую, а не через прямую карту «наблюдение → действие».
04:32 — Video World Models (Видео-модели мира)
Идея: Базовая модель предсказывает будущие кадры видео, изучая физику, геометрию и динамику среды.
Преимущество: Видео — плотное представление того, как эволюционирует мир. Пиксели становятся универсальным мостом между разными роботами (cross-embodiment).
Тезис: «Если модель мира может правильно „представить“ (dream) будущее в пикселях, то робот сможет выполнить действие в моторах».
06:09 — ОЧЕНЬ КРУТОЙ КОНЦЕПТ! DreamZero: World Action Models (Модели мира и действий)
Что такое DreamZero от Nvidia: Первая масштабированная World Action Model (WAM) на базе видео-диффузии (14B параметров, архитектура Wan 2.1). Совместно денойзит (предсказывает) будущие видеокадры и действия робота в одном процессе.
Почему это важно? То, что мы считаем генерацией смешных мемов оказалось мощным инструментом для работы в реальном мире. ИИ видит чашку и ее надо переставить. И он просто генерит видео +1 секунда от текущего состояния, где он передвигает чашку…и следует результату в реальном мире. Модель сначала видит “сон”, а потом уже его реализует в реальном мире. Пока оценивается как GPT2. Это самый начальный уровень.
Принцип: Моторные действия — это высокомерные непрерывные сигналы, похожие на пиксели. Поэтому их можно генерировать совместно.
Корреляция: «Если видео-предсказание работает — действие работает. Если видео галлюцинирует — действие проваливается.»
Zero-shot generalization: Способность выполнять задачи и глаголы, никогда не встречавшиеся в обучении.
Скорость: Через оптимизации (DreamZero-Flash) 14B модель работает в реальном времени — 7 Гц замкнутого цикла (150 мс латентность на GB200).
Cross-embodiment: Адаптация к новому роботу за 30 минут игровых данных, сохраняя zero-shot генерализацию.
07:46 — Масштабирование сбора данных
Телеобучение (чере VR-шлем) отходит на второй план. Это рабочая схема, но слишком медленная на масштабе. Еще есть UMI – интерфейс в виде руки робота, которым люди делают задачи.

Почему это важно? Телеуправление ограничено конечным временем на одного робота 24 часами в сутки. И это физическое ограничение для софтверной задачи.
Тезис: «Вычисления теперь равны среде и данным» (compute = environment = data).
Проблема: Роботические данные традиционно собираются через телеоперацию — это дорого и медленно.
Решение: Отказ от телеоперации в пользу массового сбора эгоцентрического видео (видео от первого лица от человека).
Данные: Разнообразие важнее повторений. WAM лучше учатся из гетерогенных данных, чем VLA из тысяч повторов одной задачи.
Автопилот TESLA, который более популярен в СМИ, собирает информацию точно таким же способом. Водитель едет, а система собирает и обрабатывает данные о процессе вождения.
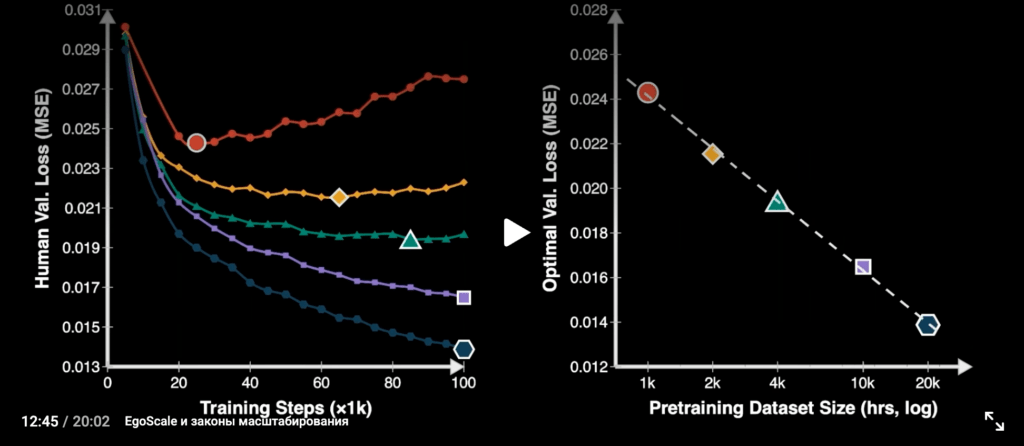
11:06 / 12:22 — EgoScale и законы масштабирования
Проект EgoScale: изучает видео записи от первого лица. И это позволяет ускорить точность работы робота и повысить скорость. Эти данные добавляются в существующие датасеты, но тенденция очевидна – телеуправление скоро станет ненужным.

Обучение на 20 854 часах эгоцентрического человеческого видео (в 20+ раз больше предыдущих датасетов).
9 869 сцен, 6 015 типов задач, 43 237 объектов.
Scaling Law: Обнаружена лог-линейная зависимость между объемом человеческих данных и валидационным лоссом (R² ≈ 0.9983).
Loss коррелирует с реальным роботом: Предсказуемое улучшение метрики напрямую переносится на физическую манипуляцию.
Почему это важно? Чем больше набор данных для обучения, тем больше эффективность. Это совпадает с историей развития обычных GPT-моделей. поэтому, так важны данные. И это запускает импульс на технологии “цифровых двойников”.
Transfer:Предобучение на человеческих данных + 50 часов выровненных человек-робот данных + 4 часа робот-данных.
Результат: +54% к успешности на 22-степенной роботизированной руке.
One-shot adaptation: Обучение новой задаче по одной демонстрации.
15:39 / 16:55 — DreamDojo и дорожная карта развития робототехники
DreamDojo: Платформа/концепция для автоматизированного исследования и самообучения роботов (аналог автоматического исследования в LLM).
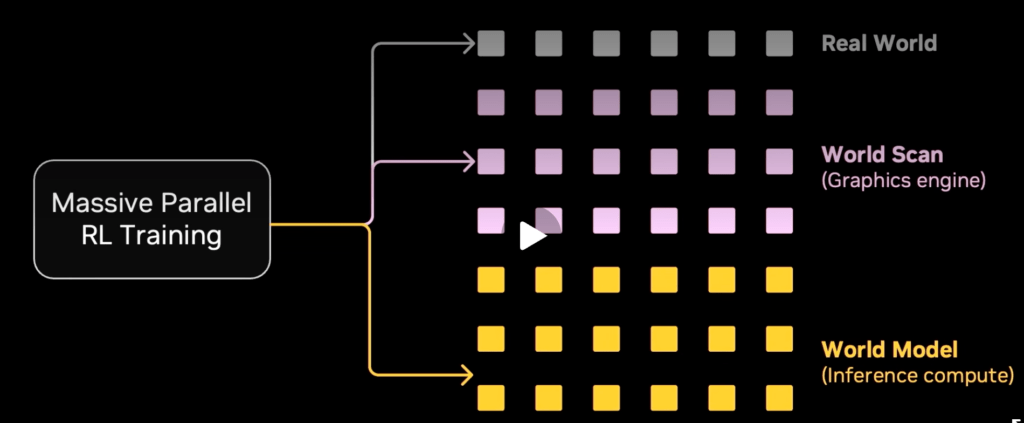
Physical Turing Test: Jim Fan утверждает, что мы пройдем физический тест Тьюринга (робот неотличим от человека в физических задачах) через 2–3 года.
Почему это поколение: «Наше поколение родилось в нужное время, чтобы решить проблему робототехники» — вычислительные ресурсы, данные и алгоритмы созрели одновременно.